
Transformer
Transformer
自从 2017 年 Google 发布一篇名为《Attention is all you need》的论文,基于transformer的网络模型便层出不穷,特别是以 Bert 和 GPT 为代表的一些语言模型实现了在多种NLP领域任务上超前的性能 ,更是将transformer的热度带向的顶峰。
2023年,openAI推出的基于GPT4的ChatGPT,其在多个领域都展现出高水平的智能,更是让人们相信基于Transformer这条路可以实现强人工智能。
Transformer 结构
![]()
Transformer主要是由Encoder和Decoder组成,这两部分的结构很相似,主要构成成分是注意力层(Attention Layer)。本文主要是对Transformer这一结构做出一定介绍,网上其实已经有很多介绍了,但很多时候并不是很全面和清晰,笔者在学习的时候发现想找一个全面介绍并不是很容易。
输入
对于LLM(large language model)其本质的输入是一段文本,然后输出也是一段文本,我们的目的就是学习一个文本到文本的映射$\textbf{Y} = f(\textbf{X})$。当然对于计算机来说,它并不能直接处理文字信息,于是我们需要对输入文本进行转换,即把输入文本变成数字(其实是变成一系列词向量),这一过程分为两个步骤:1. 分词,2. 词嵌入。
分词(Tokenize)
分词顾名思义就是将一段文本切分成一个一个“词语”,这里一个一个“词语”就叫做Token(也可以翻译为词元),每一个token用一个整数来表示,这种形成token和整数一一对应的形式就叫做词表。比如下面就是一个简单的词表:
1 | tokens |
对人类来说分词似乎是一个自然的过程,比如:“I like eating ice cream.”,一个自然的分词结果就是【’I’, ‘ ‘, ‘like’, ‘ ‘, ‘eating’, ‘ ‘, ‘ice’, ‘ ‘, ‘cream’, ‘.’】,这种分词方法被称为word base分词。
但这种分词方式有一个明显的弊端,以英语为例,英语单词往往存在单复数,各种时态,主被动等等不同的形式,这样就需要对所有这些单词都进行表示,那么就会导致最终的词表特别大,同时也会让两个本身意义很接近的词分成两个不同的数,例如:cat和cats。
第二个很容易想到的分词方法是character base分词。顾名思义,将每一个字母和标点都作为一个token。首先这种分词方法,词表大小肯定不会很大。以英文为例,字母一共就26个,加上大小写,数字,标点,特殊符号等等,总共也不会很多。但这种分词同样也是有弊端的,这种分词,每一个token缺乏单词的语义信息,并且分词的结果较长,增加了文本表征的成本。
所以现在广泛使用的是上述两种分词方法的折中,即subword base分词器。举例来说,“I like eating ice cream.”可能被分词为【’I’, ‘ ‘, ‘like’, ‘ ‘, ‘eat’, ‘ing’, ‘ ‘, ‘ice’, ‘ ‘, ‘cream.’】,最明显的区别就是eating被拆分成两个subword:eat和ing,这样做的好处是两个token都有一定意义,同时也可以缩减词表大小,例如:eat,eating,drink,drinking,按照word base进行分词,需要4个不同数来表示;如果是subword base分词,则只需要3个数来表示,eat,drink,ing。
subword base分词器可以说是现在大模型分词的主流分词方法,不过值得一提的是,如果单纯对中文进行分词还是更多地使用character base分词,这是因为中文每一个字是有明确意义的,且不存在多种表现形式(单复数等等这种),这样词表大小也不会很大。
常见的subword base分词算法有Byte Pair Encoding (BPE),openAI从GPT2开始就一直使用这种分词方法。bert使用的是wordpiece算法,可以看做是BPE算法的一种变种,另外还有Unigram LM算法。这些算法这里后续有机会再介绍。
词嵌入(word embedding)
结合上述分词的介绍,我们知道输入文本,根据词表,转化为一串数字(这个往往是分词器的功能),那么词嵌入就是将每一个数字映射到一个高维空间,每一个数字用一个向量来表示。一个朴素的想法就是用one-hot进行编码。举例来说,一个token的id=2,那么就用$e_2 = [0, 1, 0,\ldots, 0]$这个单位向量进行表示,$e_i \in \mathbf{R}^n$,$n$是词表大小。但这种编码有很大的问题,就是这些高维向量丢失了token本身的含义,比如对于很多意思相近的token,我们也期望它们在高维空间里的向量表示比较接近,同时这种one-hot编码有维度灾难的问题。除了这种强稀疏性的编码,我们可以选择稠密的编码方式,这种编码如何实现呢?这里暂时不进行详细介绍,它同样很重要,但不介绍不会影响后面的理解。
简单来说,我们会得到一个embedding矩阵$M\in \mathbf{R}^{n\times d}$,$n$是词表大小,$d$是高维向量的维度。根据词表中的token id能查到对应的词向量。
Remark:这里有个认知需要澄清一下,虽然上面一直说用一个高维向量来表示这个token id,其实这种说法不是很合适。token id本身没有意义,它对应的那个token才是有意义的,而现实中所有的token一起构成的是一个真正的高维空间。相比token本身这个空间,最后那个embedding向量其实是一个低维的,所以这里使用embedding这个词。embedding本身的意思是嵌入,就是将一个高维的token嵌入到一个低维空间,用一个$d$维向量来表示。
位置编码(position encoding)
经过上面介绍,我们知道输入一段文本,经过分词和embedding会得到一个$s \times d$为的矩阵,其中$s$是分词后的长度,$d$是embedding维度。
这里有一个小问题,不同的文本得到的矩阵其行维度是不一样的,这该如何解决呢?其实也很简单,假设Transformer接受的输入长度一个定值“seq_length=2048”,那么对于行数不足2048的矩阵进行补齐操作就行(可以补0,也可以是补其他的),超过的进行截断。
那么什么是位置编码?为什么需要位置编码?
首先回答第一个问题。位置编码,顾名思义:对序列中的词的位置进行编码。有些地方也称为position embedding。
现在回答第二个问题。对于任何一门语言,单词在句子中的位置以及排列顺序是非常重要的,它们不仅是一个句子的语法结构的组成部分,更是表达语义的重要概念。一个单词在句子的位置或排列顺序不同,可能整个句子的意思就发生了偏差。
- I do not like the story of the movie, but I do like the cast.
- I do like the story of the movie, but I do not like the cast.
上面两句话所使用的的单词完全一样,但是所表达的句意却截然相反。那么,引入词序信息有助于区别这两句话的意思。
Transformer模型抛弃了RNN、CNN作为序列学习的基本模型。我们知道,循环神经网络本身就是一种顺序结构,天生就包含了词在序列中的位置信息。当抛弃循环神经网络结构,完全采用Attention取而代之,这些词序信息就会丢失,模型就没有办法知道每个词在句子中的相对和绝对的位置信息。因此,有必要把词序信号加到词向量上帮助模型学习这些信息,位置编码就是用来解决这种问题的方法。
现在最常用的位置编码是RoPE,也称旋转位置编码,RoPE 具有更好的外推性,这促进了对长上下文窗口的支持,这个课题日后有机会再聊。这里给出几篇相关的介绍:
- 十分钟读懂旋转编码(RoPE)
- Transformer Architecture: The Positional Encoding
- 一文读懂Transformer模型的位置编码
- 一文通透位置编码:从标准位置编码、旋转位置编码RoPE到ALiBi、LLaMA 2 Long
将位置编码和输入文本的词向量相加,便可以得到Encoder层的输入了。
Encoder
Transformer的一个Encoder-layer主要由两部分组成:Attention和FFN(Feedforward networks),有时候也称为MLP(Multilayer Perceptron,多层感知机)。
Attention
Attention的实现方式有很多,最常见的还是scaled dot product attention
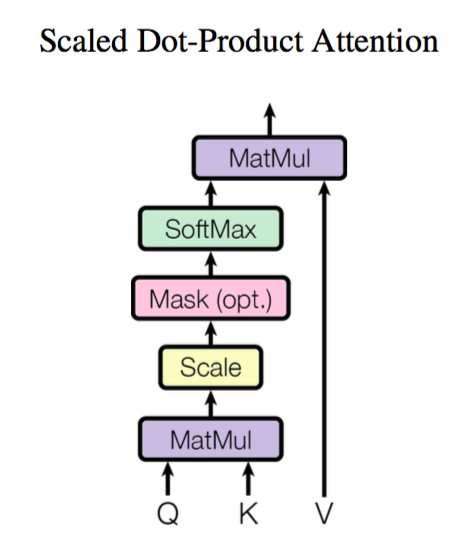
这里先主要对attention的数学计算进行介绍。
首先attention的输入是$X\in \mathbf{R}^{s\times d}$,其中$s$是输入的token长度,$d$是embedding维度。通过三个矩阵$W_Q$,$W_K$,$W_V$,将输入$X$映射成query:$Q$,key:$K$和value:$V$矩阵。
$$
Q = XW_Q, \quad
K = XW_K, \quad
V = XW_V \tag{1}
$$
$W_Q$,$W_K$,$W_V$的维度分别是:$d \times d_q$,$d \times d_k$,$d \times d_v$。一般情况下$d_q = d_k = d_v = d$(维度不一样也可以,只要符合矩阵计算的维度即可)。
这样得到的$Q$, $K$, $V$的维度分别是$s\times d$,Scaled Dot-product Attention 计算公式如下:
$$
Attention(Q,K,V) = softmax\left(\frac{Q K^{\top}}{\sqrt{d}}\right)V \tag{2}
$$
这里的softmax是按最后一维进行归一化(即行和为1)。Attention计算的结果同样是一个矩阵,维度为$s\times d$。
Multi-head attention
对与现在的大模型,大多使用多头注意力机制,即,Multi-head Attention(MHA)。MHA首先通过线性映射将$Q,K,V$序列映射到特征空间,每一组线性投影后的向量表示称为一个头 (head),然后在每组映射后的序列上再应用 Scaled Dot-product Attention: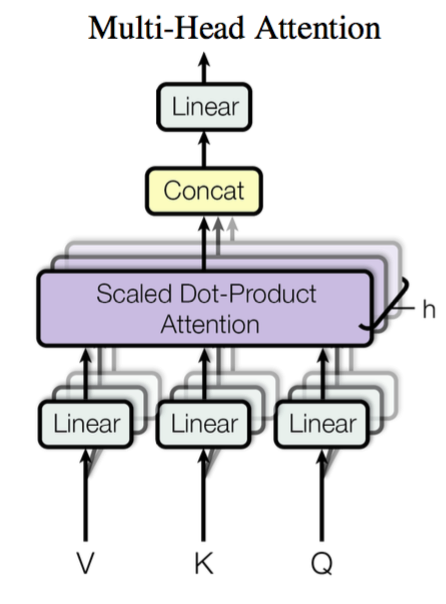
每个注意力头负责关注某一方面的语义相似性,多个头就可以让模型同时关注多个方面。因此与简单的 Scaled Dot-product Attention 相比,Multi-head Attention 可以捕获到更加复杂的特征信息。
$$
head_i = \text{Attention}(QW^{Q}_i, KW^{K}_i, VW^{V}_i)
$$
其中$W^{Q}_i, W^{K}_i,W^{V}_i$的维度均是$d \times d_i$,那么MultiHead就将每个$head_i$拼起来,即:
$$
\text{MultiHead}(Q,K,V) = \text{Concat}(head_1, \ldots, head_h)
$$
一般情况下,$d_i$会设定为一个常数,即$d_i = \bar{d}_k$,MultiHead的计算结果是一个$s \times h\bar{d}_k$的矩阵(Concat是按行拼接)。往往也会令$h\bar{d}_k = d$,这样MultiHead的结算结果和单个head计算的结果维度就完全一样了。例如在标准的BERT里面,embedding维度$d = 768$,head个数$h=12$,这样每个head attention 维度$\bar{d}_k = 768 / 12 = 64$。事实上,即使MultiHead的输出维度不等于$s\times d$也没问题,后面在接一个线性变换即可。
Feedforward network
标准的Transformer Encoder/Decoder中还包括前馈神经网络,其实就是一个两层的全连接网络(MLP)。它单独地处理序列中的每一个词向量,也被称为 position-wise feed-forward layer。常见做法是让第一层的维度是词向量大小的 4 倍,然后以 GELU 作为激活函数。对于一个维度为$s\times d$的矩阵来说,该矩阵中的每一行都会通过这个MLP网络,
$$
y = W_2 (\text{Gelu}(W_1x + b_1))+ b_2 \tag{3}
$$
其中$W_1 \in \mathbb{R}^{d_{ff} \times d}$,$W_2 \in \mathbb{R}^{d\times d_{ff}}$,$x \in \mathbb{R}^d$,$d_{ff} = 4d$。
Layer Normalization
Layer Normalization 负责将一批 (batch) 输入中的每一个都标准化为均值为零且具有单位方差;Skip Connections 则是将张量直接传递给模型的下一层而不进行处理,并将其添加到处理后的张量中。
向 Transformer Encoder/Decoder 中添加 Layer Normalization 目前共有两种做法: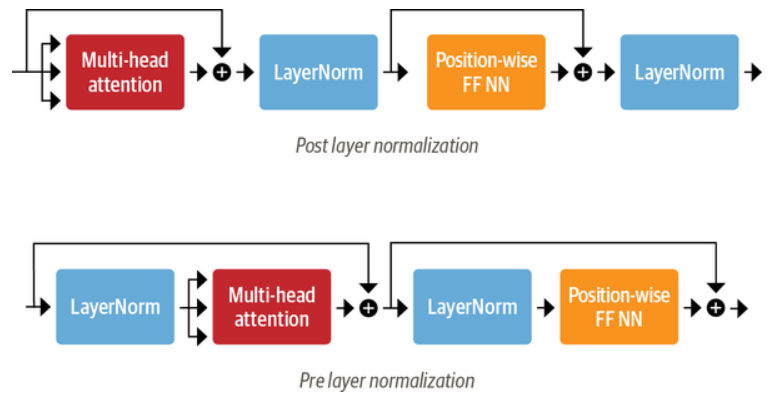
- Post layer normalization:Transformer 论文中使用的方式,将 Layer normalization 放在 Skip Connections 之间。 但是因为梯度可能会发散,这种做法很难训练,还需要结合学习率预热 (learning rate warm-up) 等技巧;
- Pre layer normalization:目前主流的做法,将 Layer Normalization 放置于 Skip Connections 的范围内。这种做法通常训练过程会更加稳定,并且不需要任何学习率预热。
Decoder
其实Decoder层基本单元和Encoder层几乎完全一样,在标准的Transformer中,Decoder 与 Encoder 最大的不同在于 Decoder 有两个注意力子层,如下图所示: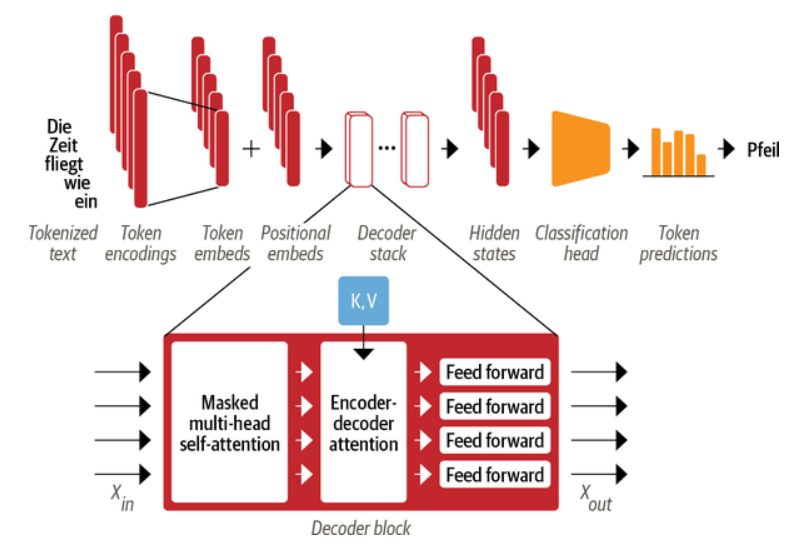
Masked multi-head self-attention layer:确保在每个时间步生成的词语仅基于过去的输出和当前预测的词,否则 Decoder 相当于作弊了;
Encoder-decoder attention layer:以解码器的中间表示作为 queries,对 encoder stack 的输出 key 和 value 向量执行 Multi-head Attention。通过这种方式,Encoder-Decoder Attention Layer 就可以学习到如何关联来自两个不同序列的词语,例如两种不同的语言。 解码器可以访问每个 block 中 Encoder 的 keys 和 values。
与 Encoder 中的 Pad Mask 不同,Decoder 的 Mask 是一个下三角矩阵。
Decoder的输入相关细节:在训练的时候,
- 初始decoder的time step为1时(也就是第一次接收输入),其输入为一个特殊的token,可能是目标序列开始的token(如<bos>),也可能是源序列结尾的token(如<eos>),也可能是其它视任务而定的输入等等,不同源码中可能有微小的差异,其目标则是预测翻译后的第1个单词(token)是什么;
- 然后<bos>和预测出来的第1个单词一起,再次作为decoder的输入,得到第2个预测单词;
- 后续依此类推;
举一个具体的例子如下:
样本:“我/爱/机器/学习”和 “i/ love /machine/ learning”
训练:
把“我/爱/机器/学习”embedding后输入到encoder里去,最后一层的encoder最终输出的outputs [10, 512](假设我们采用的embedding长度为512,而且batch size = 1),此outputs 乘以新的参数矩阵,可以作为decoder里每一层用到的$K$和$V$;
将<bos>作为decoder的初始输入,将decoder的最大概率输出词 A1和‘i’做cross entropy计算error。
将<bos>,”i” 作为decoder的输入,将decoder的最大概率输出词 A2 和‘love’做cross entropy计算error。
将<bos>,”i”,”love” 作为decoder的输入,将decoder的最大概率输出词A3和’machine’ 做cross entropy计算error。
将<bos>,”i”,”love “,”machine” 作为decoder的输入,将decoder最大概率输出词A4和‘learning’做cross entropy计算error。
将<bos>,”i”,”love “,”machine”,”learning” 作为decoder的输入,将decoder最大概率输出词A5和终止符做cross entropy计算error。
上述训练过程是挨个单词串行进行的,那么能不能并行进行呢,当然可以。可以看到上述单个句子训练时候,输入到 decoder的分别是:
<bos>
<bos>,”i”
<bos>,”i”,”love”
<bos>,”i”,”love “,”machine”
<bos>,”i”,”love “,”machine”,”learning”
将这些输入组成矩阵,这些输入组成矩阵形式如下:
[<bos>
<bos>,”i”
<bos>,”i”,”love”
<bos>,”i”,”love “,”machine”
<bos>,”i”,”love “,”machine”,”learning”]
可以将上述矩阵中的每一行补全:
[<bos>,”i”,”love “,”machine”,”learning”
<bos>,”i”,”love “,”machine”,”learning”
<bos>,”i”,”love “,”machine”,”learning”
<bos>,”i”,”love “,”machine”,”learning”
<bos>,”i”,”love “,”machine”,”learning”]
然后再乘以一个下三角的mask 矩阵既可。这就是我们需要输入矩阵。这个mask矩阵就是 sequence mask,其实它和encoder中的padding mask 异曲同工。
这样将这个矩阵输入到decoder(其实你可以想一下,此时这个矩阵是不是类似于批处理,矩阵的每行是一个样本,只是每行的样本长度不一样,每行输入后最终得到一个输出概率分布,作为矩阵输入的话一下可以得到5个输出概率分布)。
这样就可以进行并行计算进行训练了。


