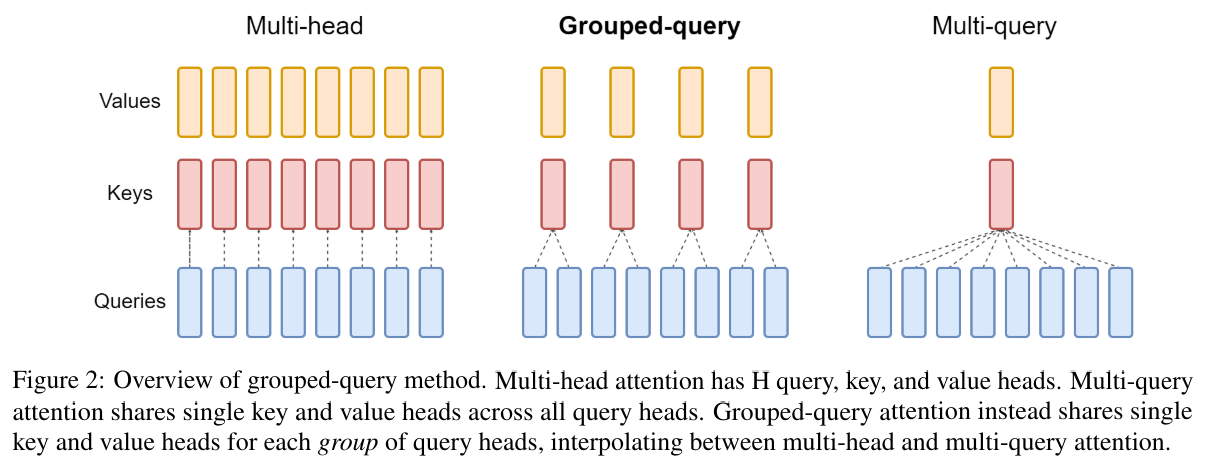
MHA, MQA, GQA
MHA (Multi-Head Attention)
我们知道多头注意力机制(MHA)是Transformer中一个非常重要的部分。相比与单头注意力机制,MHA将query,key,value分别映射到不同的子空间,从而每个头可以从不同的角度来学习特性,增加网络的表征能力。
这听起来很美好,但现实很残酷,由于大模型在推理时,是一个一个token进行推理输出的,所以当需要推理的文本很长时,那么推理计算的时间复杂度就会上升,为了降低时间复杂度,提升推理速度,我们有了KV-Cache技术。这是一种空间换时间的技巧,(后续有机会再详细掰扯)。KV-Cache确实可以提升推理速度,但是代价就是需要的显存变多了。为了降低显存,只能降低参数量,于是乎MQA(Multi-Query Attention)被提出来了。
MQA(Multi-Query Attention)
MQA的想法非常简单,就是原来每个head,都对应一组query,key,value矩阵,那么现在让不同的head都共享同一个key,value矩阵,这样不就减少了key和value矩阵的参数量了吗。举例来说:假设一个输入$x$的维度为(1, 512, 512), d_model = 512, num_head = 16, 这样每个dim_head=512/16 = 32,每个head的$Q, K, V$的维度是(1, 512, 32)。MHA中不同head的$K, V$不共享,即$K, V$的总参数为512*512,而MQA中不同head,共享同一组$K, V$,此时$K, V$的总参数为512*32,变成原来的1/16了。
由于共享了多个头的参数,限制了模型的表达能力,MQA虽然能好地支持推理加速,但是在效果上略逊MHA一筹,(相比其他修改hidden size或者head num的做法,MQA效果要更好)。那么有没有综合MQA和MHA两者的优点的呢?既能减少MQA模型能力的损失,又相比MHA需要更少的缓存,答案就是GQA(Grouped-Query Attention)。
GQA(Grouped-Query Attention)
分组注意力机制(GQA)的想法也非常简单。在MQA里,所有的head共享了同一组(K,V)导致模型能力损失了。那么现在我只让一部分head共享了同一组(K,V)。举例:现在有16个head,现在每4个head共享一组(K,V),虽然参数量减少的不那么明显了,但是相应的模型能力不会损失太多。下图里清晰地描述了MHA,MQA,GQA三者之间的区别: